해당 게시글은 기록과 자료 공유를 위해 작성합니다.
NKS로 구성된 쿠버네티스 시스템에서 워커노드를 재부팅 이후로 시스템이 무너지는 현상이 발생했는데, 조회를 해보니 calico, CSI, kube-proxy 같은 코어 이미지들이 워커노드에 존재하지 않아 컨테이너가 올라오지 못해 발생하였습니다.
이는 k8s에서 노드의 디스크 용량이 부족하게 될 경우에 가비지 컬렉션이 동작하여 특정 기간 동안 사용되지 않은 이미지들을 삭제하여 용량을 확보를 하는데, 해당 코어 이미지가 삭제가 되고 난 이후로 레지스트리에서 자동으로 받아오지 못하여 워커노드가 무너지는 현상이었습니다.
https://kubernetes.io/ko/docs/concepts/architecture/garbage-collection/
가비지(Garbage) 수집
쿠버네티스가 클러스터 자원을 정리하기 위해 사용하는 다양한 방법을 종합한 용어이다. 다음과 같은 리소스를 정리한다: 종료된 잡 소유자 참조가 없는 오브젝트 사용되지 않는 컨테이너와 컨
kubernetes.io
이는 특히 폐쇄망 환경으로 이루어진 쿠버네티스 클러스터에서 발생하기 쉬운데, 이는 Habor 같은 사설 레지스트리에 이
미지 파일을 별도 관리하거나 Proxy 등을 통해 해결하여야 합니다.
https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/
Pull an Image from a Private Registry
This page shows how to create a Pod that uses a Secret to pull an image from a private container image registry or repository. There are many private registries in use. This task uses Docker Hub as an example registry. 🛇 This item links to a third party
kubernetes.io
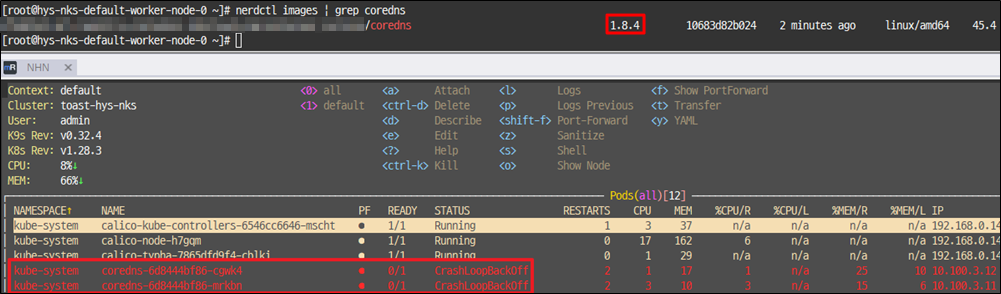
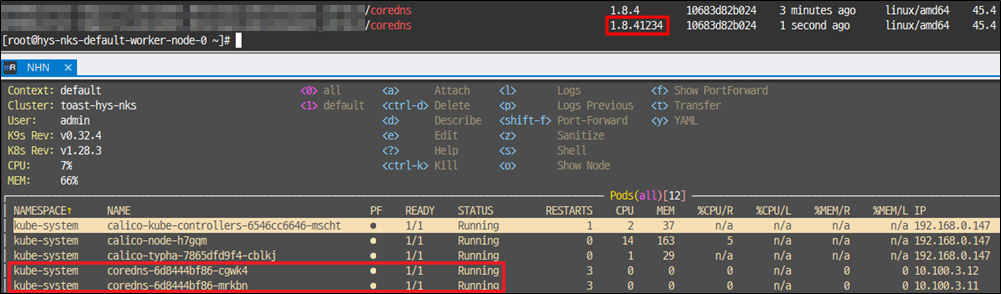
또는 워커노드에 nerdctl 등을 통해 ImagePullBackOff가 발생하는 이미지를 직접적으로 받아 온 후에 컨테이너를 살리는 방법이 있습니다.
이미지를 받아오는 방법은 두가지 정도로 제안될 수 있는데, 공식 레포지토리에서 받아오거나, NHN 레지스트리에서 받아오는 방법입니다.
1. 공식 레포지토리
# 공식 레포지토리
kubernetesui/dashboard
k8s.gcr.io/pause
k8s.gcr.io/kube-proxy
kubernetesui/dashboard
kubernetesui/metrics-scraper
quay.io/coreos/flannel
quay.io/coreos/flannel-cni
calico-kube-controllers
calico-typha
calico-cni
calico-node
coredns/coredns
k8s.gcr.io/metrics-server-amd64
....
# Kube-proxy 이미지를 복구하고 싶은 경우
nerdctl pull k8s.gcr.io/kube-proxy/[$Failed Image]
nerdctl tag k8s.gcr.io/kube-proxy/[$Failed Image]
nerdctl rmi k8s.gcr.io/kube-proxy/[$Failed Image]
2. NHN 레지스트리
nerdctl pull harbor-kr1.cloud.toastoven.net/container_service/[$Failed Image] # 이미지를 가져옴
nerdctl tag harbor-kr1.cloud.toastoven.net/container_service/[$Failed Image] # 가져온 이미지명을 Yaml에서 요구하는 이미지로 변경
nerdctl rmi harbor-kr1.cloud.toastoven.net/container_service/[$Failed Image] # 변경전 이미지 삭제
이미지 장애 상태 구현하기 위해 coredns의 yaml을 수정하여 불능 상태로 만들었습니다.



복구 과정은 아래와 같습니다.